

Co to jest plik Robots.txt? Definicja.
Zawartość strony (spis treści)
Plik Robots.txt to plik tekstowy znajdujący się na serwerze internetowym, który informuje roboty wyszukiwarek, jakie strony i sekcje strony powinny być lub nie powinny być indeksowane.
Plik Robots.txt jest często stosowany w celu zablokowania wyszukiwarek przed indeksowaniem niechcianych stron, takich jak strony testowe, strony wykluczone z powodu duplikacji treści lub strony, które nie powinny być udostępniane publicznie. Może również pomóc w optymalizacji indeksowania stron przez wyrażanie preferencji dotyczących częstotliwości odwiedzin i czasu spędzonego przez roboty na stronie.
Plik Robots.txt jest zwykle umieszczany w katalogu głównym witryny i jest czytany przez roboty wyszukiwarek podczas ich pierwszej wizyty na stronie. Jest to prosta, ale skuteczna metoda kontroli indeksowania strony przez wyszukiwarki internetowe.
Przy okazji, jeśli chcesz dostawać gorące i przydatne informacje tak jak ten wpis “Prawidłowy plik robots.txt -do czego służy?”, to zapisz się na newsletter poniżej (tak, jest całkowicie ZA DARMO):
Dlaczego plik Robots.txt jest ważny?
Plik Robots.txt jest ważnym elementem optymalizacji stron internetowych z kilku powodów:
- Kontrola indeksowania strony – Dzięki plikowi Robots.txt można kontrolować, które strony i sekcje witryny mają być lub nie mają być indeksowane przez roboty wyszukiwarek. Jest to szczególnie ważne w przypadku stron testowych, stron z duplikowaną zawartością lub stron, które nie powinny być udostępniane publicznie.
- Optymalizacja czasu i zasobów – Poprzez wyrażanie preferencji dotyczących częstotliwości odwiedzin i czasu spędzonego przez roboty na stronie, plik Robots.txt pomaga zoptymalizować czas i zasoby wyszukiwarek, co może przyczynić się do szybszego indeksowania i wyświetlania wyników w wyszukiwarce.
- Zwiększenie prywatności – Dzięki plikowi Robots.txt można ukryć niektóre sekcje strony przed indeksowaniem, co zwiększa prywatność i bezpieczeństwo witryny.
- Poprawa doświadczenia użytkownika – Plik Robots.txt pomaga wyszukiwarkom skoncentrować się na ważnych sekcjach strony, co może poprawić doświadczenie użytkownika i zwiększyć ruch na stronie.
Podsumowując, plik Robots.txt jest ważnym narzędziem optymalizacji stron internetowych, które pozwala kontrolować indeksowanie strony przez roboty wyszukiwarek, zoptymalizować czas i zasoby wyszukiwarek oraz zwiększyć prywatność i bezpieczeństwo witryny.
Crawlery, czyli roboty indeksujące są na tyle zaawansowane, że automatycznie NIE indeksują stron, które są mało istotne lub powielają (duplikują) wersje innych stron.

Mimo to, istnieją 3 główne powody, dla których chcesz użyć pliku robots.txt.
- Zapobiegasz indeksowaniu zasobów
- Chcesz efektywnie wykorzystać budżet indeksowania (crawl budget): Googlebot może przeznaczyć więcej crawl budget na indeksowanie stron, które są naprawdę ważne.
- Chcesz zablokować strony niepubliczne
![Crawl Budget – czym jest i jak wpływa na SEO? [definicja, przykłady]](https://unicornads.pl/wp-content/uploads/2022/12/crawl-budget-budzet-indeksowania.png)
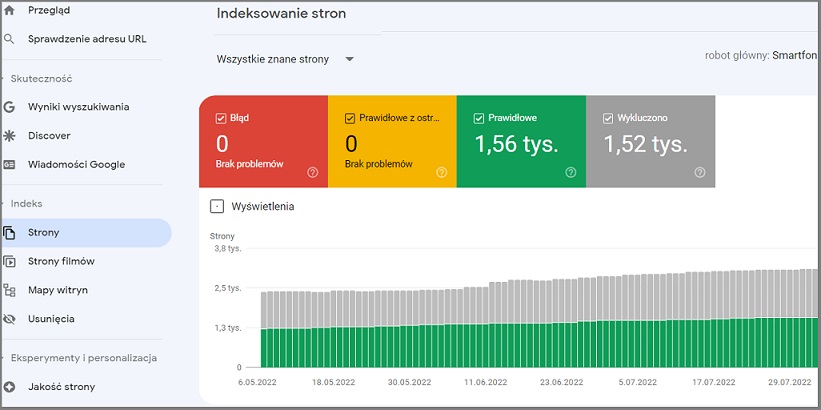
Możesz sprawdzić, ile stron masz zaindeksowane w Google Search Console.
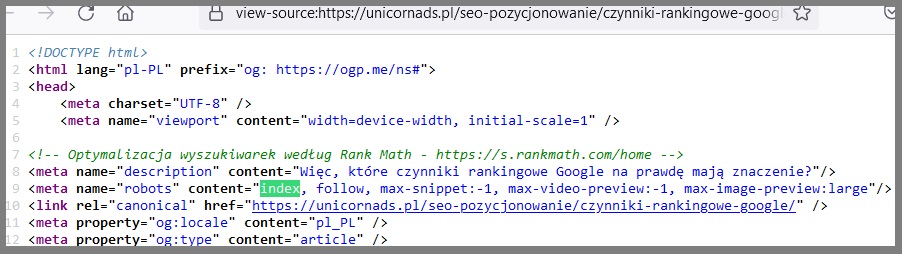
Jeśli robot Google nie zaindeksuje strony, to znaczy, że jej „nie widzi”.
Zasady tworzenia pliku robots.txt
Oto podstawowe zasady dotyczące tworzenia pliku robots.txt:
- Plik Robots.txt jest plikiem tekstowym i powinien być umieszczony w katalogu głównym witryny.
- Plik Robots.txt musi nazywać się dokładnie “robots.txt” i nie może mieć innej nazwy ani rozszerzenia.
- Plik Robots.txt musi być pisany w języku angielskim lub w języku zgodnym z normą ISO-8859-1.
- Każda sekcja pliku Robots.txt musi zaczynać się od linii “User-agent”, a następnie wskazuje się nazwę robota, np. “User-agent: Googlebot”.
- Dla każdej sekcji “User-agent” należy podać, które strony i sekcje witryny mają być lub nie mają być indeksowane przez robota, np. “Disallow: /admin/”.
- W przypadku wskazania wielu sekcji dla jednego robota, każda sekcja musi być oddzielona linią pustą.
- Plik Robots.txt może zawierać komentarze, które zaczynają się od znaku “#” i są ignorowane przez roboty wyszukiwarek.
- Nie można blokować dostępu do pliku Robots.txt dla robotów wyszukiwarek.
- Nie można wykorzystywać pliku Robots.txt do ukrywania stron przed użytkownikami lub zwiększania swojej pozycji w wynikach wyszukiwania.
Podsumowując, plik Robots.txt powinien być pisany zgodnie z powyższymi zasadami, aby zapewnić jego poprawne działanie i umożliwić kontrolowanie indeksowania witryny przez roboty wyszukiwarek.
To tylko jeden z wielu sposobów wykorzystania pliku robots.txt. Google ma nawet oficjalny przewodnik na temat tworzenia różnych reguł, które możesz użyć, aby zablokować lub zezwolić robotom na indeksowanie różnych stron Twojej witryny.
Pamiętaj, żeby Twój plik Robots.txt był łatwy do znalezienia
Tak, to bardzo ważne, aby plik Robots.txt był łatwo dostępny i widoczny dla robotów wyszukiwarek. Aby upewnić się, że plik jest łatwy do znalezienia, należy umieścić go w głównym katalogu witryny i umieścić link do niego w stopce strony lub w pliku .htaccess.
Dodatkowo, można dodać wpis w pliku robots.txt, który informuje roboty wyszukiwarek o lokalizacji pliku sitemap witryny, co ułatwi indeksowanie i wykrywanie nowych treści na stronie. W tym celu należy dodać wpis “Sitemap” z odnośnikiem do pliku sitemap.
Przykład
https://unicornads.pl/robots.txt
U mnie wygląda to tak:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://unicornads.pl/sitemap_index.xml(Pamiętaj, że w pliku robots.txt rozróżniana jest wielkość liter. Upewnij się więc, że nazwa pliku zawiera małą literę „r”)
Sprawdź błędy i pomyłki
Aby sprawdzić błędy i pomyłki w pliku robots.txt, można skorzystać z różnych narzędzi dostępnych w Internecie. Oto kilka popularnych narzędzi:
- Google Search Console – Jest to narzędzie od Google, które umożliwia sprawdzenie, czy plik robots.txt działa prawidłowo. Po zalogowaniu się do konta Google Search Console, należy wybrać właściwą witrynę, a następnie przejść do zakładki “Pokrycie indeksu” i kliknąć na przycisk “Testuj zasadę”. W ten sposób można przetestować, czy plik robots.txt blokuje dostęp do wybranych stron.
- Ahrefs – To narzędzie SEO oferujące między innymi opcję sprawdzenia pliku robots.txt. Wystarczy wpisać adres strony i kliknąć na przycisk “Wyświetl plik robots.txt”, aby zobaczyć jego zawartość i sprawdzić, czy występują w nim błędy.
- Robots.txt Tester – To bezpłatne narzędzie online, które umożliwia sprawdzenie pliku robots.txt pod kątem błędów i pomyłek. Wystarczy wpisać adres strony i kliknąć przycisk “Sprawdź plik robots.txt”, a narzędzie wyświetli raport z informacjami na temat ewentualnych błędów.
- Screaming Frog SEO Spider – Jest to płatne narzędzie SEO, które umożliwia przeprowadzenie pełnej analizy strony, w tym sprawdzenie pliku robots.txt. Wystarczy wpisać adres strony i kliknąć na przycisk “Start”, a narzędzie przeprowadzi analizę i pokaże ewentualne błędy w pliku robots.txt.
- Bing Webmaster Tools – Jest to narzędzie SEO od Microsoft, które umożliwia sprawdzenie pliku robots.txt i wykrycie ewentualnych błędów. Po zalogowaniu się do konta Bing Webmaster Tools, należy wybrać właściwą witrynę, a następnie przejść do zakładki “Konfiguracja witryny” i wybrać “robots.txt Tester”.
Na szczęście Google ma bardzo dobre narzędzie do testowania dyrektyw z plików robots.txt.

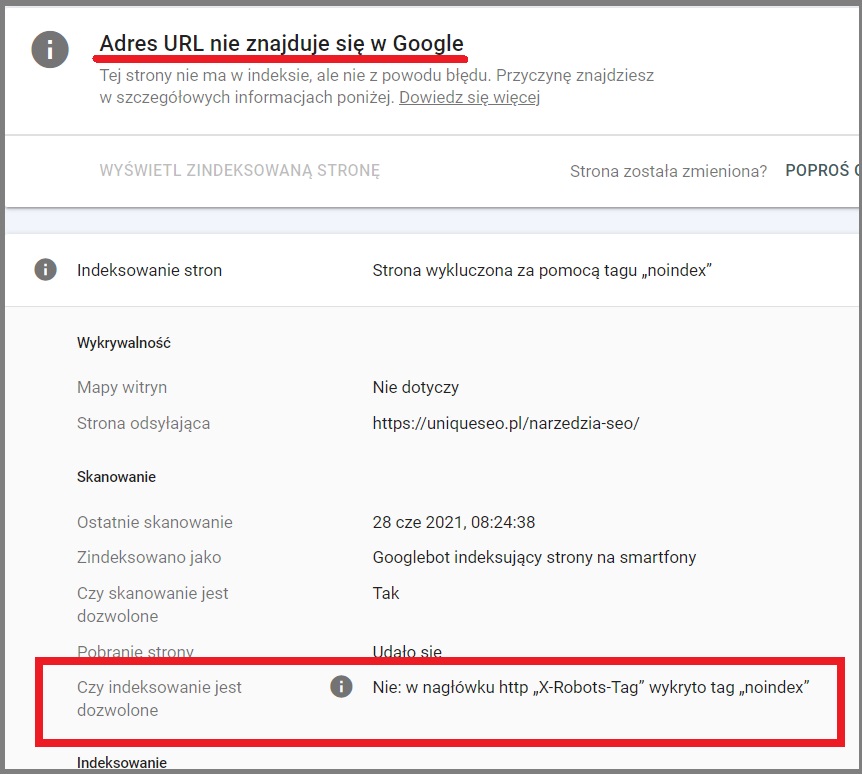
Dlaczego używać pliku robots.txt, skoro można blokować strony za pomocą metatagu „noindex”?
Plik robots.txt i meta tag “noindex” służą do różnych celów i stosuje się je w różnych sytuacjach.
Plik robots.txt jest stosowany do zarządzania indeksacją strony przez roboty wyszukiwarek, tzn. umożliwia kontrolowanie, które strony na stronie internetowej mogą być indeksowane, a które powinny być pominięte. Oznacza to, że plik robots.txt nie blokuje bezpośrednio indeksacji, ale raczej informuje roboty wyszukiwarek, które strony powinny zostać pominięte. Jest to szczególnie przydatne w przypadku dużych stron internetowych z wieloma podstronami, gdzie nie wszystkie strony są ważne z punktu widzenia SEO.
Z drugiej strony meta tag “noindex” jest bezpośrednim poleceniem dla robotów wyszukiwarek, aby pominięły stronę w procesie indeksacji. Jest to przydatne, gdy chcesz całkowicie wykluczyć pewne strony lub sekcje strony z indeksacji, np. gdy chcesz ukryć stronę z wersji testowej przed użytkownikami lub gdy chcesz wykluczyć stronę z indeksacji, aby uniknąć duplikacji treści.
Podsumowując, stosowanie pliku robots.txt i meta tag “noindex” zależy od celu, jaki chcemy osiągnąć. Plik robots.txt jest przydatny do kontrolowania, które strony powinny być indeksowane, a które nie, natomiast meta tag “noindex” jest przydatny, gdy chcemy całkowicie wykluczyć stronę z indeksacji.
Podsumowanie
Teraz chciałbym usłyszeć od Ciebie:
Który fragment artykułu był dla Ciebie najbardziej zaskakujący?
A może masz jakieś pytanie.
Tak czy inaczej, zostaw teraz krótki komentarz poniżej.

FAQ – krótkie pytania i szybkie odpowiedzi
Gdzie jest plik robots txt?
Plik robots.txt znajduje się w głównym katalogu witryny internetowej. Można go zlokalizować pod adresem URL http://www.twojadomena.pl/robots.txt, gdzie “twojadomena.pl” to adres Twojej witryny internetowej.
Aby zmienić plik robots.txt na swojej stronie internetowej, należy wprowadzić odpowiednie zmiany w pliku, a następnie przesłać go na serwer za pomocą protokołu FTP lub za pomocą panelu administracyjnego hostingu, jeśli jest dostępny. Upewnij się, że plik robots.txt ma odpowiednie uprawnienia do odczytu przez roboty wyszukiwarek, aby zapewnić jego poprawne funkcjonowanie.